
sequelize belongsToMany vs hasMany
22 Nov 2018 | sequelize associationssequelize belongsTo vs hasOne 포스트에서 1대1 관계에 대해서 알아보았다. 이번에는 hasMany와 belongsToMany가 어떤 차이점이 있고 언제 쓰이는지에 대해서 알아보았다. 물론 이것 역시 공식문서를 번역한 것이나 다름없다.
One-To-Many associations (hasMany)
hasMany의 경우 하나의 source 모델을 여러개의 Target 모델과 연결시킨다. 그리고 Target의 경우 단 하나의 soucce모델을 참조 할 수 있게 된다. 예를 들자면 여러개의 City(도시)를 가지는 Country(국가)를 들 수 있다. 각 모델을 생성하기 위해 간단히 아래와 같이 define했다고 가정하자.
const City = sequelize.define('city', { countryCode: Sequelize.STRING });
const Country = sequelize.define('country', { isoCode: Sequelize.STRING });
Country는 여러개의 City를 가지므로 Country hasMany City는 자연스럽다. 반대로 City는 단 하나의 Country만을 가지는 것이 자연스러운 그런 관계이다. 따라서 관계를 아래와 같이 설정할 수 있다.
Country.hasMany(City, {as : "Cities"});
위와 같이 설정하면 Country는 두가지 메서드를 가지게 된다. getCities와 setCities이다. Country가 여러 cities들을 가져오는 것은 자연스러운 일이다. 한편 반대로 City는 한개의 Country를 가지므로, City모델에는 Country를 참조하는 countryId 또는 country_id라는 attribute가 생긴다.
꼭 country_id를 가지고 관계를 설정하지 않아도 된다. default는 id지만 sourceKey 옵션을 통해 isoCode를 가지고 관계를 설정하게 할 수도 있다.
// Here we can connect countries and cities base on country code
Country.hasMany(City, {foreignKey: 'countryCode', sourceKey: 'isoCode'});
City.belongsTo(Country, {foreignKey: 'countryCode', targetKey: 'isoCode'});
Belongs-To-Many associations (belongsToMany)
n:m 관계 설정시 사용한다.
한 User가 여러개의 Project에 참여할 수 있고, 또한 하나의 Project에 여러명의 User들이 참여하는 상황이라면 n:m 이라고 할 수 있다. 그러나 이런 관계는 데이터베이스에서 직접 구현 할 수 없다. 대신, 이러한 관계를 두 개의 일대다 관계로 분리해야한다. 즉, 또 다른 하나의 table, 즉 연결 테이블이라 불리는 또 다른 모델이 필요하다(예를 들어 UserProject 테이블). 코드를 보자면 아래와 같다.
Project.belongsToMany(User, {through: 'UserProject'});
User.belongsToMany(Project, {through: 'UserProject'});
이렇게 관계를 설정해 준다면, UserProject라는 테이블이 하나 자동으로 생성되고, 이 테이블(모델)에는 projectId와 userId가 존재하게 된다. 즉, 관계를 중계해주는 하나의 테이블(모델)이 생성되는 것이다. 이때 테이블의 이름을 정하는 through 속성은 필수적이다.
이렇게 설정할 경우 좋은 장점은, UserProject를 생성했지만 Project와 User테이블 각각에 메서드가 추가된다는 점이다. 예를 들어 Project모델에 getUsers, setUsers, addUser, addUsers 등의 메서드가 추가되고, User모델에 getProjects, setProjects, addProject, addProjects 등의 메서드가 추가된다.
또한 as옵션, foreignKey옵션을 사용할 수 있다.
User.belongsToMany(Project, { as: 'Tasks', through: 'worker_tasks', foreignKey: 'userId' })
Project.belongsToMany(User, { as: 'Workers', through: 'worker_tasks', foreignKey: 'projectId' })
위의 예시처럼, User를 Workers라는 별칭으로 지정할 수 있고, worker_tasks라는 join table에 userId라는 이름으로 attributes를 직접 지정할 수 있다. 이렇게 하면 Project 모델에서 getWorkers()나 addWorkers()처럼 사용할 수 있다. 마찬가지로 Project를 Tasks라는 이름으로 사용할 수 있게 된다.
그러나 이렇게만 한다면 worker_tasks 테이블, UserProject 테이블에는 userId와 projectId라는 속성밖에 없다. 그래서 UserProject 테이블에 추가적인 attributes를 추가할 수 있는 방법이 있다.
const User = sequelize.define('user', {})
const Project = sequelize.define('project', {})
const UserProjects = sequelize.define('userProjects', {
status: DataTypes.STRING
})
User.belongsToMany(Project, { through: UserProjects })
Project.belongsToMany(User, { through: UserProjects })
User에 새로운 Project를 추가하고 싶은 경우, options.through를 setter에 추가한다.
user.addProject(project, { through: { status: 'started' }})
위와 같은 n:m관계에서 Query문을 날릴 땐, through와 구체적인 attributes를 명시해줘야 한다.
User.findAll({
include: [{
model: Project,
through: {
attributes: ['createdAt', 'startedAt', 'finishedAt'],
where: {completed: true}
}
}]
});
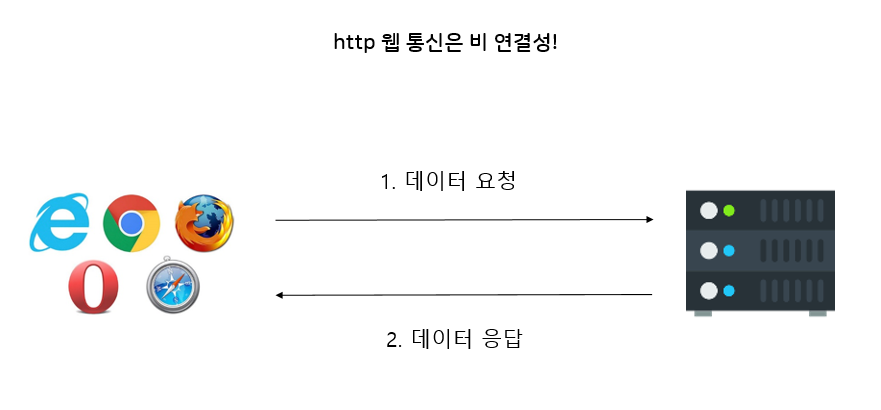 이 과정이 한차례 지나가면,
이 과정이 한차례 지나가면,
 이렇게 서로 모르는 사이, 서로 접속이 끊어진 사이가 되는 것이다.
이렇게 서로 모르는 사이, 서로 접속이 끊어진 사이가 되는 것이다.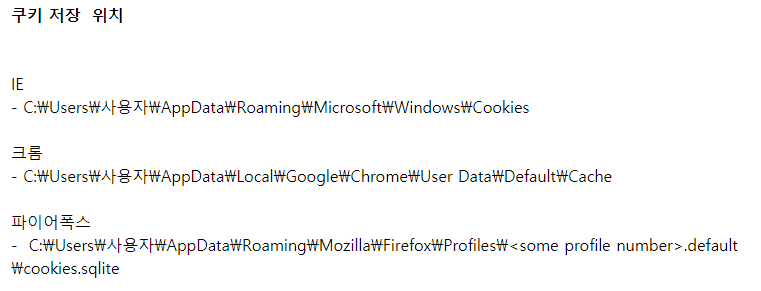
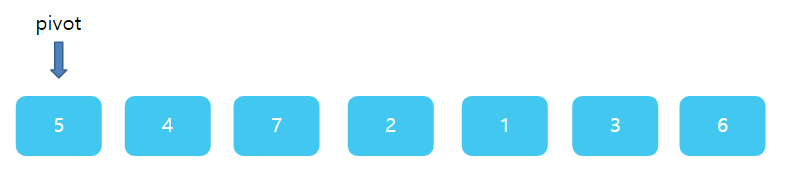
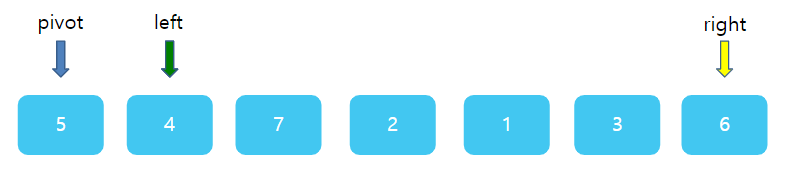
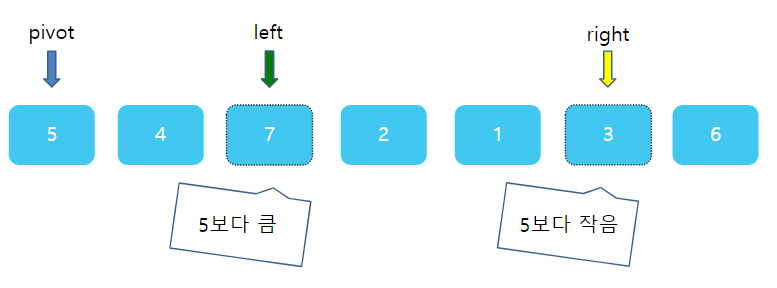
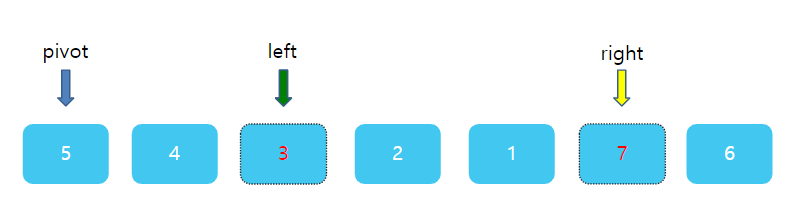
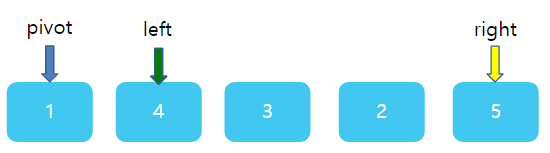
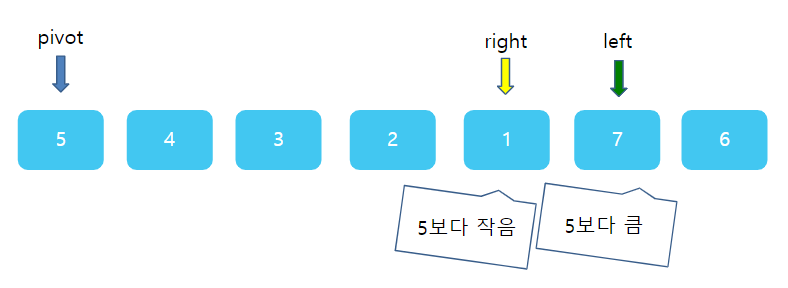 그런데 이번엔 조금 주의해야한다. right와 left의 상대적 위치가 바뀌었다. left가 왼쪽에, right가 오른쪽에 있어야 하는데 서로 자리가 뒤바껴있다. 바로 이 때가 한번의 분류를 끝마칠 때이다. right과 left가 있는 1 과 7 사이에 딱 5가 들어간다면? 그렇다면 5의 왼쪽에 있는 수는 모두 5보다 작을 것이며, 5의 오른쪽에는 모두 5보다 클것이다. 따라서 right 자리에 pivot을 넣고, 원래의 피봇자리인 첫 번째 자리에 right가 가르키고 있는 값 1을 주면 된다.
그런데 이번엔 조금 주의해야한다. right와 left의 상대적 위치가 바뀌었다. left가 왼쪽에, right가 오른쪽에 있어야 하는데 서로 자리가 뒤바껴있다. 바로 이 때가 한번의 분류를 끝마칠 때이다. right과 left가 있는 1 과 7 사이에 딱 5가 들어간다면? 그렇다면 5의 왼쪽에 있는 수는 모두 5보다 작을 것이며, 5의 오른쪽에는 모두 5보다 클것이다. 따라서 right 자리에 pivot을 넣고, 원래의 피봇자리인 첫 번째 자리에 right가 가르키고 있는 값 1을 주면 된다.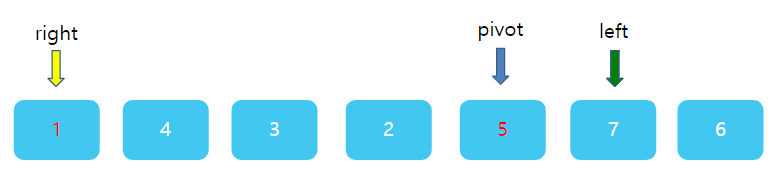
 그리고
그리고
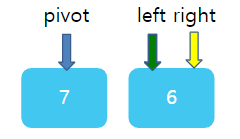 이렇게 두개의 배열이 있는 것이고, 각각 독립적으로 위에서 했던 방법 그대로 적용하면 된다.
이렇게 두개의 배열이 있는 것이고, 각각 독립적으로 위에서 했던 방법 그대로 적용하면 된다.